搜索时间/(×104)
列表[2]的方式实现对象字典。该方式的结构介于数组和链表
8 6
之间,既避免了数组浪费存储空间的缺点,又克服了链表搜
4
索效率低的不足。
2
2.2 散列表构建对象字典基本原理
0
一个函数(哈希函数,也叫作散列函数),使得每个对象的索
引和子索引都与一个函数值(即数组下标)相对应,于是用这
0
个数组单元来存储这个对象;也可以简单地理解为,按照索
引和子索引为每一个对象“分类”,然后将这个对象存储在相应“类”所对应的地方。数组定义如下:
ODIndex iOD[HT_WIDTH]其中,HT_WIDTH为散列表的宽度。
但是,不能够保证每个对象的索引和子索引与函数值是一一对应的,因此,极有可能出现对于不同的对象,却计算出了相同的函数值,这样就产生了冲突[2]。
对象的索引和子索引通过哈希函数[2]转化为散列地址。应尽可能地使索引和子索引经过哈希函数得到一个随机的地址,以便将对象均匀地分布到整个地址区间中。如果保存在散列表中的索引和子索引不连续分布,映射函数具有伪随机性,则可将对象合理地得分布到散列表中。
由于对象字典访问的频繁性,映射函数需要足够简单以减少运算时间,这里采用如下哈希函数:
HS _index = mod(((index×ran_num) >>
(1)
shift _num+ sub_index),HS _index_range) 其中,HS_index为散列地址;mod()为取模运算;index为对象索引;ran_num为随机因子;shift_num为位移因子; sub_index为对象子索引;HS_index_range为散列地址的范围常量。
如前所述,不能保证从 index和 sub_index到 HS_index的映射不会重叠,会产生冲突。这里处理冲突的方法采用链地址法[2],将映射到同一个散列地址处多于一个的对象组成链表,即形成该散列地址对应的溢出表。从散列表的相应位置可以访问其对应的溢出表。
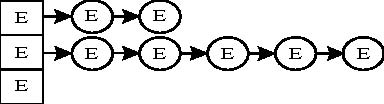
用散列表构建的对象字典逻辑结构如图 1所示,散列表地址范围为 M,E代表一个索引项,N代表一个未使用的散列表项。
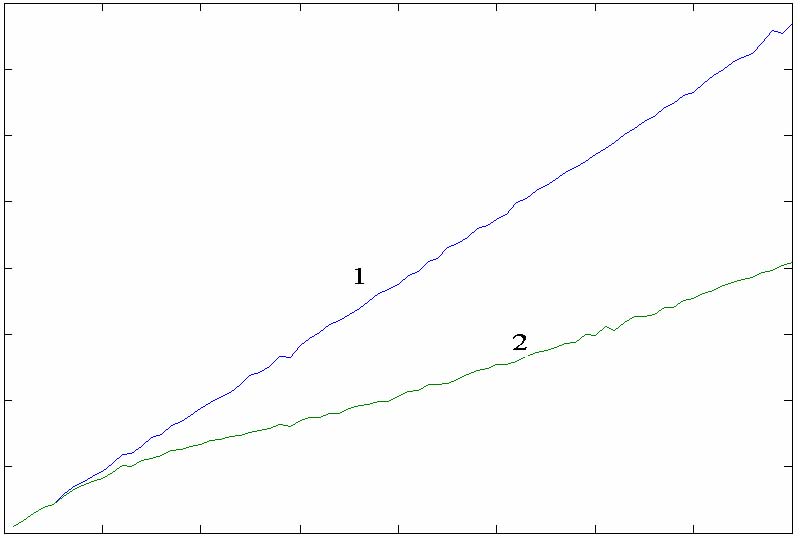
图 2 随机因子,位移因子和搜索时间之间的关系
图 2中横坐标轴代表随机因子 ran_num,纵坐标轴代表位移因子 shift_num,竖坐标轴代表搜索时间,搜索时间的计算公式如下:
512 ni() sum = ∑∑k (2)i = 1k = 0 其中,sum为遍历 779个对象需要的搜索时间;n(i)代表样本空间中映射到散列地址 i的对象个数。sum值越小说明散列表的填充率越高。经测试可知,当 ran_num取 193, shift_num取 3时散列表填充率最高,可达 99.8%。
2.3 散列表方式构建对象字典的性能分析散列表方法是数组和链表搜索的结合。对于散列表的搜索和数组相同,但是对溢出表则采用链表的搜索方式。
数组搜索由于下标的使用,为 O(1)算法。链表只能单向搜索,如果链表中的节点为随机分布,那么平均搜索时间为 O(n),其中,n为链表的长度。
在散列表的填充率为 100%, m≥N的情况下,可以得到散列表的平均长度:
 收藏灵猫网
收藏灵猫网